News¶
v0.3.2:¶
We introduced a model for the automatic segmentation of the anatomical cross-sectional area of the patellar tendon and updated the documentation and usage examples accordingly. All models, the installer and examples can be downloaded from the DeepACSA repository.
Patellar tendon models¶
- Data:
We provide a model for the automatic segmentation of the patellar tendon anatomical cross-sectional area (ACSA) at 25%, 50%, and 75% of tendon length in healthy subjects (UNet 3+). Further information is available in the DeepACSA repository, and the model together with reliability data can be downloaded from OSF.
We evaluated two model architectures for patellar tendon segmentation: UNet-VGG16 and UNet 3+. Their performance was assessed by comparing automated predictions with manual segmentations. Reliability was evaluated and is reported in the figure below.
Overall, both models demonstrated good agreement with manual analysis, with UNet 3+ showing the most consistent performance. Detailed methodology and results are reported in our publication (Guzzi et al., 2026).
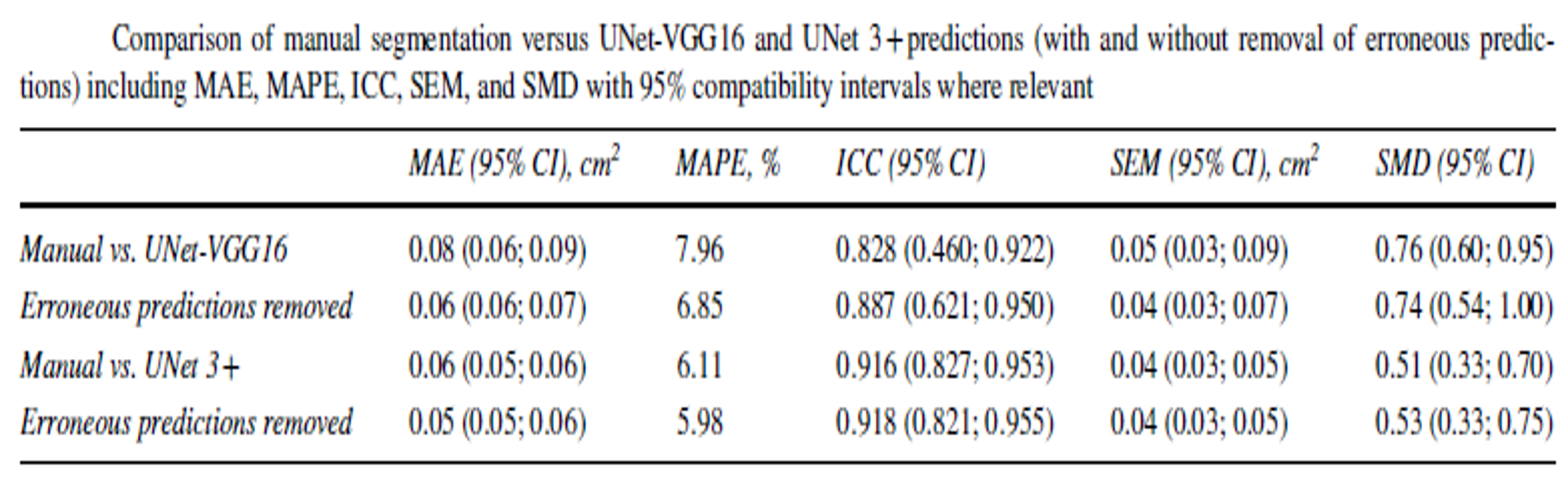
Figure 1: Comparison of manual segmentation versus VGG16 UNet and UNet 3+ predictions (with and without removal of erroneous predictions).¶
Vastus medialis model¶
- Data:
We provide a model for the automatic segmentation of the vastus medialis cross-sectional area (ACSA) in healthy participants as well participants with ACL injuries.
A UNet-VGG16 model was evaluated and compared to manual analysis. Comparability calculations and detailled methodology can be found at Tayfur et al. 2025
v0.3.1:¶
- Code:
Upgraded to Python 3.9.18 and adapted compatibility
Restructuring of the GUI
Inclusion of Mask creation inside GUI (see Data labelling)
Inclusion of Mask inspection inside GUI (see Mask / label inspection)
Removal of the need to specify image types
- Data:
We included a new model architecture as pre-trained models in the DeepACSA dataset for the RF and VL muscles. The new dataset can be accessed here These model architectures were:
We provide, together with ORBlab Michigan, models for the automatic segmentation of the biceps femoris long head at several muscle length in male, female young and adult people. More information can be found in the DeepACSA repo. The models and further informations on them can be downloaded from the respective OSF.
UNet3+ (Huang et al., 2020) for RF and VL: It uses full-scale skip connections, causing increased skip connections. These additional skip connections in between layers help to preserve data that is needed for further training. Full-scale skip connections incorporate low-level details with high-level semantics from feature maps in different scales, which is beneficial for medical image segmentation.
To summarise the results for the rectus femoris, for the visually inspected (segmented masks were visually checked for plausibility) rectus femoris images, the original architecture was slightly exceeded by the UNet 3+. Moving towards the vastus lateralis, the UNet 3+ closely followed by TransUNet outperformed the original architecture on the uninspected data. For the visually inspected data of the vastus lateralis, the UNet 3+ outperformed the other models. We provide two more models and compared them to manual analysis (Fig. 2-5). Users are adivsed to select the performing models for VL and RF. However, we still advise to test the selected model prior to usage. All models were trained using K-fold (5 folds used) cross-validation to ensure that overfitting is reduced.
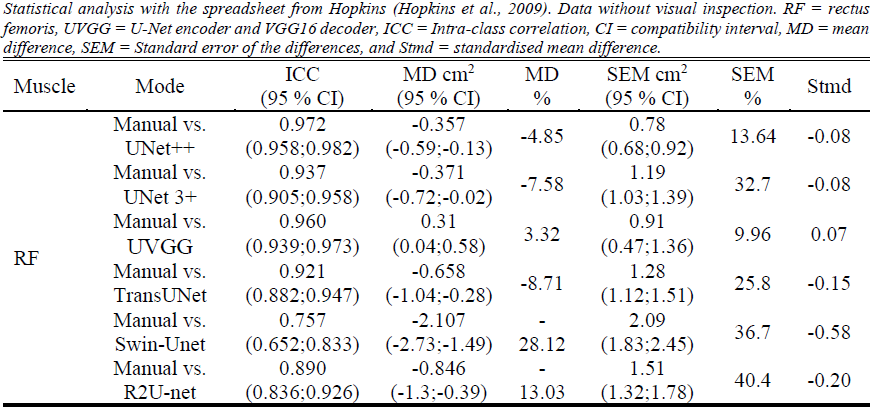
Figure 2: Comparison of RF images to manual analysis with uninspected results.¶
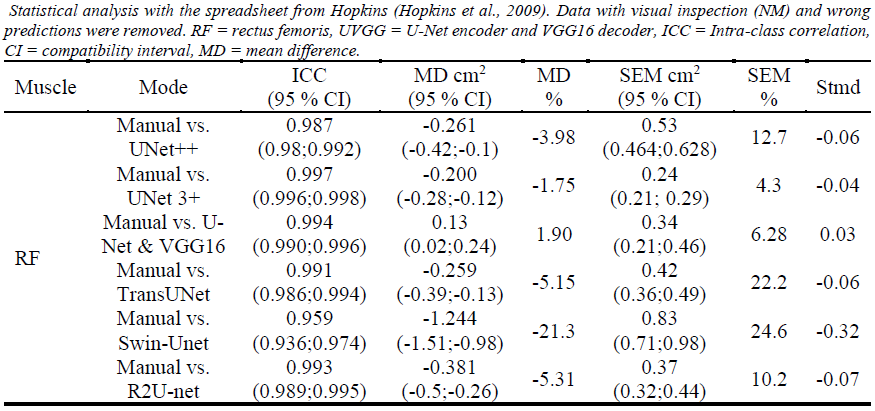
Figure 3: Comparison of RF images to manual analysis with inspected results.¶
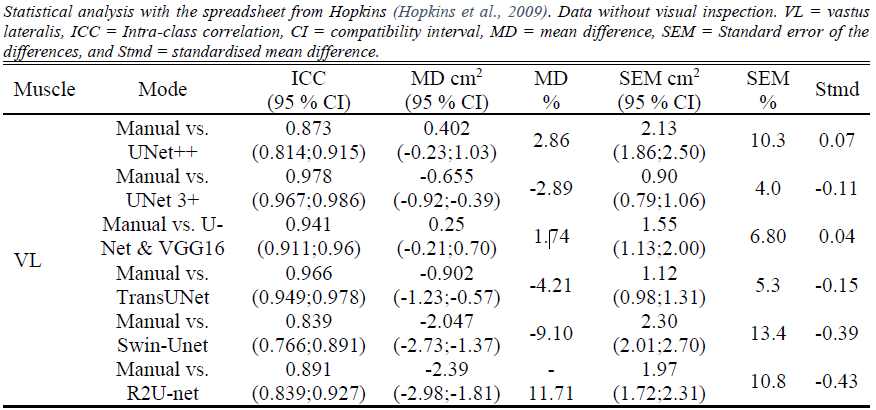
Figure 4: Comparison of VL images to manual analysis with inspected results.¶
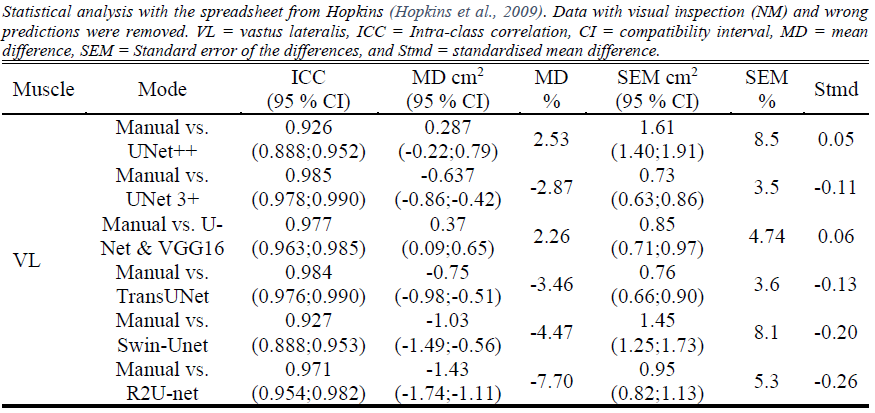
Figure 5: Comparison of VL images to manual analysis with inspected results.¶